
Comme d’habitude et fidèle à mon esprit de partage, je vous invite à découvrir les tendances en Référencement SEO qui vont façonner nos stratégies marketing SEO en 2019. Petit rappel voici le les tendances SEO que j’avais annoncées pour 2017:
- Rank Brain: comme son nom l’indique Google devient cerveau
- Le mobile et AMP: Pages accélérées pour le mobile
- Le HTTPs: le protocole d’URLs sécurisées via certificat SSL ou TLS
- L’utilisation d’angular JS et les sites en JS: ce n’est pas une mode
- Applications iOS et Androïde: pour générer de l’engagement des clients
- Résultats universels: Vidéo, image, local, Cartes et PDF
- Extraits enrichis (#0): le résultat ayant comme position zéro !
- Réputation sur les réseaux sociaux: l’engagement prime sur la popularité
- Penguin 4.0 qui est en temps réel: les liens à acquérir pour un profil sain
- Recherche vocale: on parle de 20% du volume de recherche selon Google
Depuis l’année 2018 s’est écoulée et a confirmé beaucoup de ces aspects évoqués dans mon billet de 2017 mais cette année je me concentre sur le top des tendances comme sur mon sondage sur Twitter où j’ai réussi à avoir pas moins de 68 votes et les résultats sont comme suit :
Bonjour les #seo de ce monde si vous me suivez et lisez mes articles, j’ai besoin de vous pour rédiger le prochain article sur #mozalami les tendances SEO 2018 et pour ça je vous demande de participer au sondage suivant pour prioriser. Merci d’avance
— Mohammed ALAMI (@mohammedalami) 20 octobre 2018
Donc pour bien faire nous allons couvrir ces 4 thèmes en donnant plus de poids aux topiques les plus votées à savoir JavaScript et SEO suivi de la recherche vocale.
Introduction
Le but de pareil partage est de générer des quick fix qui peuvent avoir un impact sur les rankings et donc sur le trafic que vous pouvez quantifier en valeur média (équivalent PPC) ce qui donnera de la crédibilité à votre travail en tant que Consultant SEO ou Inhouse ou en agence selon le cas.
Tout d’abord EAT (Expertise, Authoritativeness, Trustworthiness) nous a donné du fil à retordre cette année 2018 et continuera à occuper une place de choix dans nos stratégies SEO étant donné la fréquence des mises à jour de Google que nous avons connues cette année et qui vont dans ce sens. Ci-dessous la volatilité des SERPs selon CognitiveSEO :

On voir clairement une tendance aux grandes fluctuations depuis Fin 2017 et ça continue encore proche de nous fin Novembre et mi-Décembre 2018.
Ensuite l’utilisation du JavaScript pour le déploiement de sites web est en croissance et les SPA (Single Page Application) gagnent du terrain avec une domination de Angular JS suivi de près par React qui gagne en popularité comme le montre ce graphique de Google Trends :
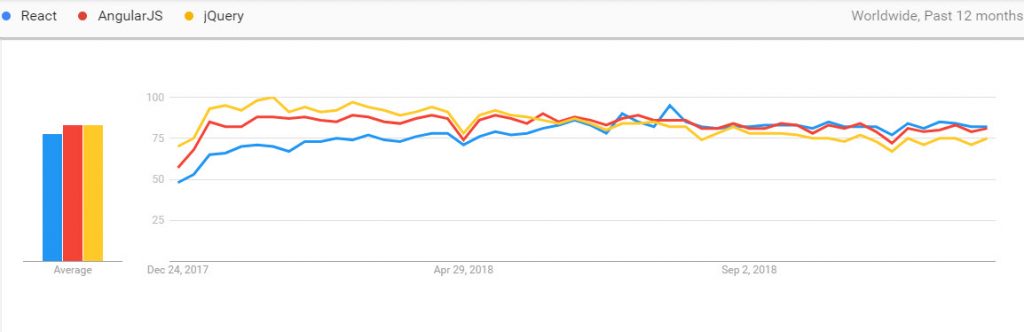
Le Semantic Mark up lui s’est enrichi ces derniers temps d’une panoplies de nouvelles propriétés et on citera Question/Réponse, FAQ (en pending), Speakable schema (en Béta), Howto …etc.
Il est intéressant de voir comment Google a changé son fusil d’épaule quand il a annoncé qu’il ne voulait pas s’appuyer sur les webmasters pour populer ses résultats vocaux comme rapporté sur mon billet sur la recherche vocale et SEO mais maintenant a sorti les tags spécialement pour Publishers propriétaires de sites de Nouvelles.
Cela nous amène à la recherche vocale qui elle aussi gagne du terrain et il est indéniable qu’il s’agit d’une tendance irréversible comme ce fût le cas du mobile en moitié de décennie.

Quelles sont donc les tendances SEO pour 2019 ?
Pour 2019, les tendances les plus importantes sont comme suit:
- EAT et Rank Brain : bien comprendre ce que veut Google en la matière
- Javascript et SEO : les bases d’une stratégie SEO pour réussir un déploiement en JS
- Semantic Mark Up : quoi de neuf dans les tags sémantiques et où allons-nous
- Recherche vocale : retour sur expérience et les conseils SEO pour y entrer
SEO pour EAT et Rank Brain
Pour cette partie je vais beaucoup m’appuyer sur les travaux de Glenn Gabe qu’il faut suivre sur Twitter notamment pour ses recherches post algo updates comme Google Medic et d’autres.

Pour rappel Google a mis à jour ses guidelines pour les réviseurs manuels (QRG) en Juillet 2018 en mettant plus l’emphase sur les signaux de qualité qui sont utilisés pour juger une page web :
 On voit clairement que Google incorpore la notion de l’expertise de l’auteur d’où la nécessité d’avoir la bio auteur sur le blog bien renseignée avec tous les liens vers les médias sociaux notamment. On voit aussi l’autorité que Google a avoué à demi-mot utiliser pour le ranking d’un site quand une nouvelle page est produite. Dans une interview avec Will Critchlow publiée le 10 décembre 2018, John Mueller devait répondre sur la notion d’autorité de domaine :
On voit clairement que Google incorpore la notion de l’expertise de l’auteur d’où la nécessité d’avoir la bio auteur sur le blog bien renseignée avec tous les liens vers les médias sociaux notamment. On voit aussi l’autorité que Google a avoué à demi-mot utiliser pour le ranking d’un site quand une nouvelle page est produite. Dans une interview avec Will Critchlow publiée le 10 décembre 2018, John Mueller devait répondre sur la notion d’autorité de domaine :
I don’t know if I’d call it authority like that, but we do have some metrics that are more on a site level, some metrics that are more on a page level, and some of those site wide level metrics might kind of map into similar things.
…
the main one that I see regularly is you put a completely new page on a website. If it’s an unknown website or a website that we know tends to be lower quality, then we probably won’t pick it up as quickly, whereas if it’s a really well-known website where we’ll kind of be able to trust the content there, we might pick that up fairly quickly, and also rank that a little bit better.
…
it’s not so much that it’s based on links, per se, but kind of just this general idea that we know this website is generally pretty good, therefore if we find something unknown on this website, then we can kind of give that a little bit of value as well.
…
At least until we know a little bit better that this new piece of thing actually has these specific attributes that we can focus on more specifically.
John Mueller
Pour le Trust ou l’indice de confiance, nous avons plutôt des indicateurs généraux comme éviter ces points qui peuvent le diminuer :
- Il ne faut pas que votre site semble être une arnaque. Assurez-vous que votre site est moderne. Utilisez un langage clair et facile à comprendre. Ceux-ci aident à vous établir en tant que source légitime.
- Ne demandez pas d’information sans raison. Soyez direct avec toutes les informations que vous demandez aux utilisateurs de fournir. Si vous souhaitez demander un nom, un numéro de téléphone ou une adresse électronique, assurez-vous que l’utilisateur sait exactement ce qu’il va en retirer et pourquoi vous lui demandez.
- Ne ressemblez pas à un site de phishing. Assurez-vous que vos URL sont toutes claires et limitez les redirections sur vos liens. De même, ne demandez pas aux utilisateurs de saisir des informations (telles que les identifiants Facebook) qu’ils n’ont pas à faire.
- Limitez vos formats de téléchargement. Les programmes et les applications peuvent faire allusion à des logiciels malveillants ou à des virus. Lorsque vous avez des téléchargements, choisissez des formats tels que .txt, .pdf, .docx, .xlsx.
Ce dernier point (trust) est particulièrement sensible quand il s’agit de YMYL Sites (Your Money, Your Life sites.). Dans ce PDF de QRG, une page YMYL est ainsi définie : « page qui pourrait influencer le bonheur, la santé, la stabilité financière ou la sécurité des utilisateurs ».

Vous m’avez vu venir, Google Medic Update en Aout 2018, a typiquement visé ce genre de sites et leurs contenus comme le rapporte Marie Haynes dans son blog. Elle a donné un exemple d’un site YMYL qui a été impacté négativement et trouvé les failles qui suivent :
- Il n’y a pas de page à propos sur ce site. Les QRG sont très clairs en déclarant qu’il devrait être évident qui est responsable de l’information sur un site.
- Le site a très peu de réputation externe. L’objectif principal de ce site semble être de vendre leur « système de tirage au sort céto ». Il n’y a rien de mal à vendre un produit mais les QRG indiquent qu’un produit doit avoir une très bonne réputation.
- Le site peut préconiser un traitement médical allant à l’encontre du consensus convenu scientifiquement.
Avant RankBrain, les ingénieurs de Google devaient ajuster et tester manuellement différentes mises à jour d’algorithmes. RankBrain a changé la donne.
En bref, RankBrain modifie lui-même l’algorithme. Selon le mot-clé, RankBrain augmentera ou diminuera l’importance des backlinks, de la fraîcheur du contenu, de la longueur du contenu, de l’autorité du domaine, etc. Ensuite, il examine comment les internautes de Google interagissent avec les nouveaux résultats de recherche. Si les utilisateurs aiment mieux le nouvel algorithme, il garde son setting. Sinon, RankBrain annule l’ancien algorithme.

Voici résumé la conclusion de Glenn pour donner suite à son analyse que vous pouvez trouver ici très complète et détaillée mais qui rejoint ce que nous avons vu à propos des QRG et EAT :
Pour les propriétaires de sites qui ont été touchés, je recommande fortement d’Analyser objectivement votre site, d’exécuter des tests utilisateur, d’adresser le bonheur de l’utilisateur (et du client) et de créer un plan d’attaque efficace pour améliorer l’ensemble de votre site.
Glenn Gabb
Pour finir sur ce sujet j’ajouterai simplement qu’il s’agit moins d’un simple tweak à vos pages en changeant les Meta et le contenu que la révision complète de votre stratégie de production par qui pourquoi, d’acquisition de liens de qui vers quoi. John Mueller a résumé ses conseils ainsi :
The quality rater’s guidelines & the old Panda blog post (« More guidance on building high-quality sites ») are good places to get ideas. The important point (in my eyes) is that this is not a « tweak h1’s, inject keywords, get links » kind of traditional SEO work, but rather you’d want to step back, understand where the site’s audience is & where it’s going, and rethink how you’d like to position the site within the 2019+-web.
John Mueller
Je sais que c’est mince et que nous n’avons pas beaucoup de matière pour faire des recommandations claires et nettes mais je pense aussi que cela doit se faire au cas par cas.
SEO pour sites web en Javascript
Lors de la création d’une page Web moderne, il existe trois composants principaux:
- HTML – Hypertext Markup Language sert d’ossature ou d’organisateur de contenu sur un site. C’est la structure du site Web et la définition du contenu statique.
- CSS – Les feuilles de style en cascade sont la conception, le faste, le glam et le style ajoutés à un site Web.
- JavaScript – JavaScript sert l’interactivité et est un composant essentiel du Web dynamique.

AJAX, ou JavaScript et XML asynchrones, est un ensemble de techniques de développement Web combinant JavaScript et XML qui permet aux applications Web de communiquer avec un serveur en arrière-plan sans interférer avec la page en cours.
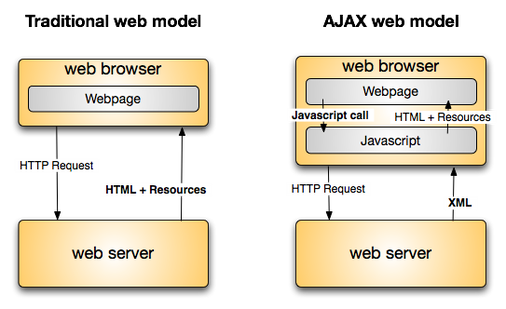
Notre objectif dans le présent billet est de mettre en évidence les défis du référencement SEO lorsque les sites Web sont activés pour JavaScript et de fournir des conseils permettant de mieux gérer les moteurs de recherche afin de maximiser le trafic SEO.
Défis du JS et corrections SEO
Le recours intensif à JavaScript pour restituer le contenu de votre page et fournir une fonctionnalité de navigation comporte des risques bien connus en termes de référencement technique, d’indexation et de capacité de linking.
Le premier défi important à noter concernant JavaScript est que tous les moteurs de recherche ne traitent pas le JS de la même manière que Google qui utilise JavaScript depuis 2008. L’idée selon laquelle Google peut explorer ces types de pages n’a rien de nouveau. En 2015, Google a annoncé qu’il pouvait analyser les fichiers JS et CSS (s’ils ne sont pas bloqués).
Times have changed. Today, as long as you’re not blocking Googlebot from crawling your JavaScript or CSS files, we are generally able to render and understand your web pages like modern browsers.
Source Google 2015
Cependant, d’autres moteurs de recherche tels que Bing, Yahoo, Ask, AOL, DuckDuckGo, Yandex et Baidu ont des problèmes avec certains frameworks JavaScript tels que React JS, Angular JS, Angular2 JS, Ember, jQuery, Knockout et Plain JS:

Source: Moz mid-2017
Down-level experience enhances discoverability – avoid housing content inside Flash or JavaScript – these block crawlers form finding the content” ” Bing
Webmaster Guidelines, 2018
Cela signifie concrètement pour la section du site en JS, nous pourrions perdre environ 5% des visites lorsque les domaines référents sont bing.com, yahoo.com et duckduckgo.com. Nous considérons ce pourcentage comme très faible et nous concentrerons nos efforts sur Google.
Pour les besoins du référencement, nous devons définir le DOM, car c’est ce que Google utilise pour analyser et comprendre les pages Web.
DOM est ce que vous voyez lorsque vous « inspectez un élément » dans un navigateur. En termes simples, vous pouvez considérer le DOM comme les étapes que le navigateur prend après la réception du document HTML pour restituer la page. Utilisé dans les navigateurs Web, le DOM est essentiellement une API, pour le balisage et les données structurées telles que HTML et XML. C’est l’interface qui permet aux navigateurs Web d’assembler des documents structurés.

Le DOM définit également la manière dont cette structure est utilisée et manipulée. Bien que le DOM soit une API indépendante du langage (non lié à un langage de programmation ou une bibliothèque spécifique), il est le plus souvent utilisé dans les applications Web pour JavaScript et le contenu dynamique.
Le DOM représente l’interface, ou « pont », qui connecte les pages Web et les langages de programmation. Le code HTML est analysé, le JavaScript est exécuté et le résultat est le DOM. Le contenu d’une page Web n’est pas (simplement) du code source, c’est le DOM. Cela le rend important.
« Dynamically inserted content, and even meta signals such as rel canonical annotations, are treated in an equivalent manner whether in the HTML source, or fired after the initial HTML is parsed with JavaScript in the DOM »
Source – Searchengineland 2015

Dans les sections suivantes, nous aborderons les principales préoccupations rencontrées avec JS quand il s’Agit d’optimisation SEO :
1. Crawlability: capacité des robots à explorer votre site.
2. Accessibilité: capacité des robots à accéder à l’information et à analyser votre contenu.
3. Latence perçue du site: AKA, le chemin de rendu critique (Critical Rendering Path)

Possibilité d’exploration
La possibilité d’exploration désigne la capacité d’un moteur de recherche d’explorer tout le contenu textuel de votre site Web, en accédant facilement à chacune de vos pages Web, sans rencontrer d’impasse imprévue. Ici, nous devons parler de 2 sujets importants:
- Bloquer les moteurs de recherche l’accès à votre JavaScript (souvent via le fichier Robots.txt)
- Liens internes appropriés, sans exploiter les événements JavaScript pour remplacer les balises HTML.
Autoriser Google à analyser vos fichiers JS
Si les moteurs de recherche ne sont pas autorisés à explorer le JavaScript, ils ne recevront pas toute l’expérience de votre site. L’outil de test Google « Fetch and Render » peut aider à identifier les ressources qui bloquent Googlebot. Assurez-vous que Google a accès à tous les fichiers JS.
Les liens internes doivent utiliser des balises d’ancrage normales dans le code HTML ou DOM.
Pour l’essentiel: n’utilisez pas les événements onclick de JavaScript pour remplacer les liens internes. Bien que les URL finales puissent être trouvées et explorées (au moyen de chaînes en code JavaScript ou de plans de site XML), elles ne seront pas associées à la navigation globale du site. Les liens internes doivent être implémentés avec des balises d’ancrage normales dans le code HTML ou DOM (à l’aide d’une balise HTML href = « www.example.com ») et non via l’utilisation de fonctions JavaScript pour permettre à l’utilisateur de parcourir le site.

La structure d’URLs
Historiquement, les sites Web basés sur JavaScript (ou « sites AJAX ») utilisaient des identificateurs de fragment (#) dans les URL. Il est utilisé pour identifier un lien d’ancrage (ou liens de saut). Ce sont les liens qui permettent de passer à un élément de contenu d’une page. Tout ce qui suit la partie de hachage unique de l’URL n’est jamais envoyé au serveur.
Les URL de hachage étaient un hack pour prendre en charge les robots d’exploration (Google veut éviter maintenant et seul Bing le supporte). Google et Bing ont développé une solution AJAX complexe, dans laquelle le signe (#!) faisait partie de l’URL : l’UX coexistait avec un fragment escaped_fragment basé sur HTML pour les robots.
Idéalement, chaque interaction d’utilisateur devrait déclencher une nouvelle URL. De cette manière, nous nous assurons que tous les signaux de Google sont alignés (méta, contenu, liens).
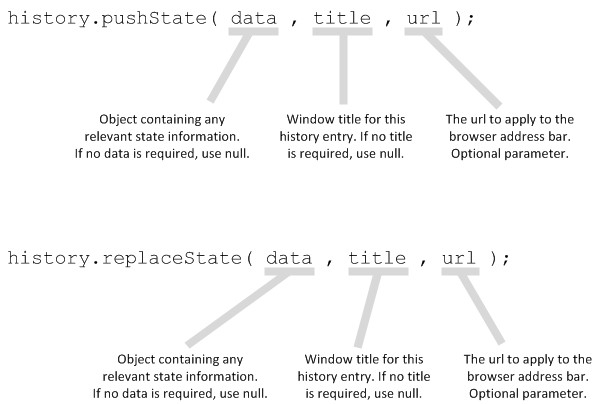
PushState History API – PushState est basé sur la navigation et fait partie de l’API History. Essentiellement, pushState met à jour l’URL dans la barre d’adresse et ne met à jour que ce qui doit être modifié sur la page. Il permet aux sites JS d’exploiter des URL « propres ». PushState est actuellement pris en charge par Google, lorsqu’il prend en charge la navigation par navigateur pour un rendu côté client ou hybride.
Exemple: vous trouverez ici un bon exemple d’implémentation de défilement infini compatible avec les moteurs de recherche, créée par John Mueller de Google. Il utilise techniquement le replaceState ().
Facilité d’obtention
En supposant qu’il s’agisse d’un robot de moteur de recherche exécutant JavaScript, il existe quelques éléments importants permettant aux moteurs de recherche d’obtenir du contenu:
- Si l’utilisateur doit interagir pour que quelque chose se déclenche, les moteurs de recherche ne le voient probablement pas.
- Si le JavaScript survient après le déclenchement de l’événement de chargement JavaScript plus ~ 5 secondes, il est possible que les moteurs de recherche ne le voient pas.
- En cas d’erreurs dans JavaScript, les navigateurs et les moteurs de recherche ne pourront pas passer et risquent de manquer des sections de pages si tout le code n’est pas exécuté.
Envisagez de tester et de passer en revue les éléments suivants:
- Confirmez que votre contenu apparaît dans le DOM.
- Testez un sous-ensemble de pages pour voir si Google peut indexer le contenu
- Vérifiez manuellement les parties de votre contenu indexables par les moteurs
- Récupérez avec Google et voyez si le contenu apparaît. (Nécessite une vérification GSC)
- La récupération avec Google est supposée se produire autour de l’événement de chargement ou avant l’expiration du délai. C’est un excellent test pour vérifier si Google pourra voir votre contenu et si vous bloquez JavaScript dans votre fichier robots.txt.
Que faire si le référencement SEO est critique
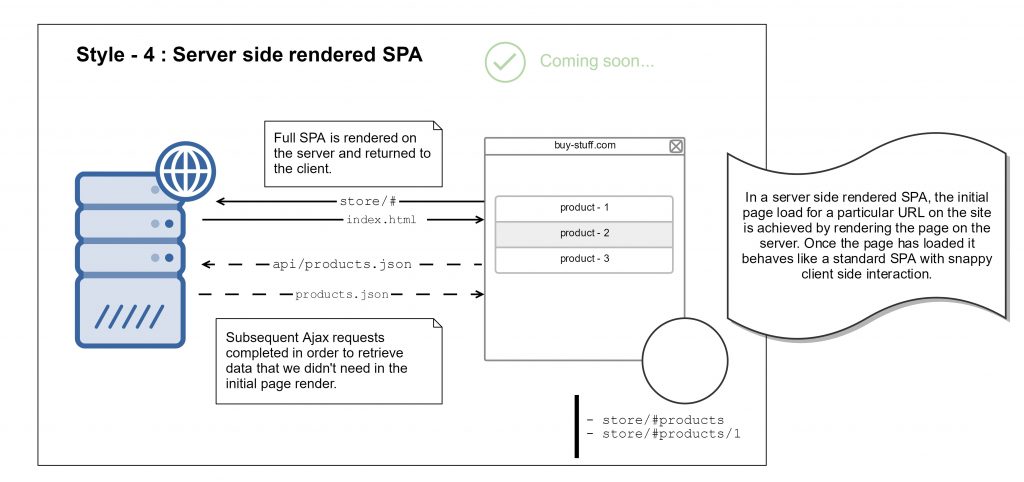
Si le référencement est critique, vous ne pouvez pas vous fier au rendu du client de SPA et vous devez vous assurer que le contenu est inclus dans les pages. Il existe deux techniques, le rendu côté serveur et le prérendering, qui permettent d’atteindre le résultat souhaité.
Rendu côté serveur
Le rendu côté serveur (SSR) intervient lorsque la page est rendue par le serveur Web dans le cadre du cycle de demande / réponse du serveur. L’état du DOM virtuel est converti en chaîne HTML, puis injecté dans la page avant son envoi au client. Lorsque la page atteint le navigateur, l’application JavaScript se monte de manière transparente sur le contenu existant.
Prérendering
Avec cette approche, vous exécutez l’application avec un navigateur sans interface graphique dans votre environnement de développement, effectuez une capture instantanée de la sortie de la page et remplacez vos fichiers HTML par cette capture instantanée dans la réponse du serveur. C’est le même concept que SSR, c’est fait avant le déploiement, pas sur un serveur actif.


Latence du site
Lorsque les navigateurs reçoivent un document HTML et créent le DOM, la plupart des ressources sont chargées telles qu’elles apparaissent dans le document HTML. Cela signifie que si vous avez un énorme fichier vers le haut de votre document HTML, un navigateur chargera d’abord cet immense fichier.
Cependant, si vous avez des ressources inutiles ou des fichiers JavaScript qui encombrent la capacité de chargement de la page, vous obtenez du « JavaScript bloquant le rendu ». Signification: votre JavaScript empêche le potentiel de la page de s’afficher comme si elle se chargeait moins rapidement (également appelée: latence perçue).

JavaScript bloquant le rendu – Solutions
1. Inline: Ajoutez le JavaScript dans le document HTML.
2. Async: rendre JavaScript asynchrone (c’est-à-dire ajouter l’attribut « async » à la balise HTML)

3. Différez: en plaçant JavaScript plus bas dans le code HTML

Remarque: Il est important que les scripts soient classés par ordre de priorité. Les scripts utilisés pour charger le contenu au-dessus du pli (above the fold) doivent être hiérarchisés et ne doivent pas être différés. En outre, tout script faisant référence à un autre fichier ne peut être utilisé qu’après le chargement du fichier référencé.
Recommandations finales
Sur la base de l’analyse ci-dessus, je résume mes recommandations comme suit:
- Autoriser Google à analyser vos fichiers JS et CSS
- Liens internes appropriés, sans tirer parti des événements JavaScript pour remplacer les balises HTML.
- Structure d’URL propre, pas d’utilisation d’identificateurs de fragment (#) ou d’URL Hashbang (#!)
- Il n’y a pas de valeur de délai d’expiration spécifique; Cependant, les sites doivent viser un chargement dans les cinq secondes.
- Confirmez que votre contenu apparaît dans le DOM.
- Envisagez de choisir un service tel que prerender.io pour résoudre les problèmes SEO.
- Minimisez le temps de chargement perçu sur le site
Toutes ces recommandations vont de pair avec nos meilleures pratiques de référencement pour les éléments de pages et la copie, qui doivent être exploités pour optimiser les pages du site (Meta, Canonicals, Alts… etc.).

Semantic Mark Up et SEO
Une brève définition du Semantic Mark Up est donnée par Google directement dans les SERPs :
Le code HTML sémantique ou balisage sémantique est un code HTML qui donne un sens à la page Web plutôt qu’une simple présentation. Par exemple, une balise <p> indique que le texte inclus est un paragraphe. Ceci est à la fois sémantique et présentationnel, car les gens savent ce que sont les paragraphes et les navigateurs savent comment les afficher.
Google comme Publisher ?!
Nous avons eu l’occasion de couvrir en long et en large cette topique dans mon billet « le marquage sémantique en référencement SEO » qui date de 2015 mais depuis bien de nouvelles propriétés ont vu le jour et ici je vais en couvrir 3 qui me semblent importantes pour nous autres référenceurs SEO de ce monde.
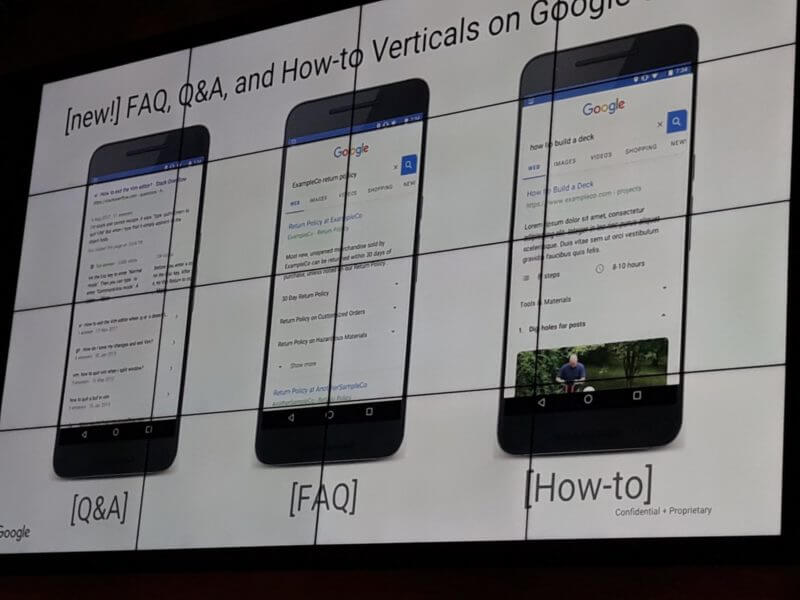
Ces trois Schema ont été confirmés par Akhil Agarwal comme étant supportés par Google en Août 2018 malgré qu’il n’y ait pas encore d’engouement de la communauté, donc une opportunité en SEO pour mieux servir les clients et acquérir des nouveaux tôt dans leur recherche de produits ou services.
Q&A Schema Mark Up
Comme d’habitude Google publie ses guidelines en même temps que l’apparition du Schema sur le site officiel Schema.org. Quand on regarde le code d’implémentation on se rend compte que celle-ci est réservée pour les pages contenant une seule question et possiblement plusieurs réponses comme le confirmait @JohnMuller sur Twitter :
Hi Modestos, just following up here — after checking with the team it turns out that QAPage markup isn’t suitable for FAQ content. We’ve updated the docs to make that clearer there too.
— 🍌 John 🍌 (@JohnMu) 4 décembre 2018
Le résultat est intéressant avec un carrousel de réponses comme sur l’Exemple ci-dessous :
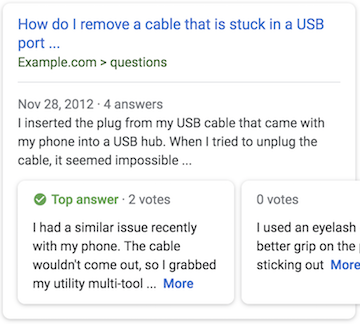
Certains pourraient se lancer dans cette entreprise pour une pièce de blog avec une question énoncée genre « comment obtenir les featured snippets » mais à mon avis cela ne fait pas de sens car dans ce cas c’est tout le billet qui en est la réponse. Je vois ce balisage plus pertinent pour les forums ou les questions posées par les internautes sur une section support.
FAQ Page Semantic Mark up
Comme on a vu, le précédant Schema est à réserver pour les pages avec une seule question. Mais Google a besoin de nos réponses quant aux recherches d’internautes sur nos produits et services de manière générale. Alors il est arrivé avec un nouveau marquage FAQPage mais qui est toujours en « pending » pour le moment.
Cependant, étant donné l’appétit que Google a en ce moment pour les questions et réponses que ce soit pour la recherche clavier ou vocale, il est recommandé de s’y mettre tout de suite.
Voici un exemple qui utilise « webpage » et FAQ en attendant qu’il soit approuvé :
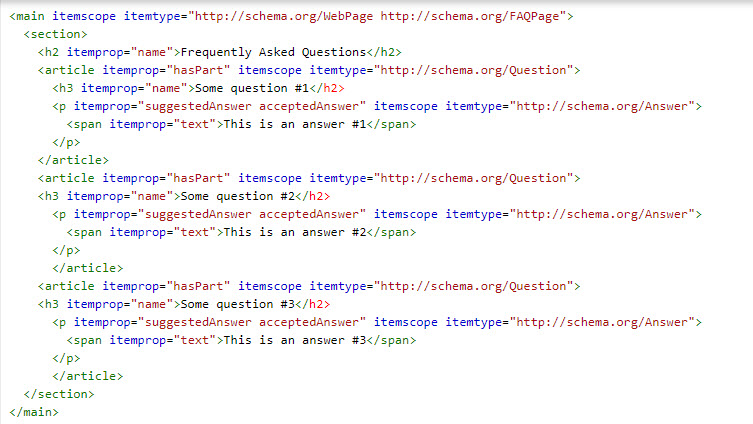
Vous pouvez voir que Google interprète bien le contenu sans erreurs :

Howto Semantic Markup
Il est intéressant de voir que Google s’intéresse de plus en plus à tout ce qui peut répondre aux interrogations des internautes (certainement pour mieux préparer son hégémonie en recherche vocale) et dans ce cadre il a sorti le Howto (comment faire) Schema déjà utilisé par Slack par exemple dans la capture écran suivante :

La beauté de ce balisage est qu’il est simple d’utilisation. L’implémentation est documentée sur le site de Schema.org et les outils de test Google sont conçus pour valider vos résultats. Et voici le code source à l’origine de ce beau résultat dans la recherche Google :

SEO et Recherche Vocale
Dans ce chapitre je vais aller plus en profondeur car il s’agit d’un changement de paradigme au même titre que nous avions vécu le switch au mobile. Pour commencer quelques statistiques qui vont vous donner envie de poursuivre la lecture :
- Aux USA 47,3 millions d’adultes ont accès à un smart speaker (comme Google home ou Echo d’Amazon) et au Canada on en dénombre 1,7 millions à la fin 2018
- Il y a 2 ans en 2016 Google a annoncé que 20% de ses recherches étaient vocales et si on se rappelle Google a fait cette annonce concernant le mobile en 2012 et en 2015 ce ratio a dépassé les 50%.
- Comscore annonce que d’ici 2020 50% de toutes les recherches seront effectuées par la voix (sans pour autant gruger dans nos recherches traditionnelles via clavier
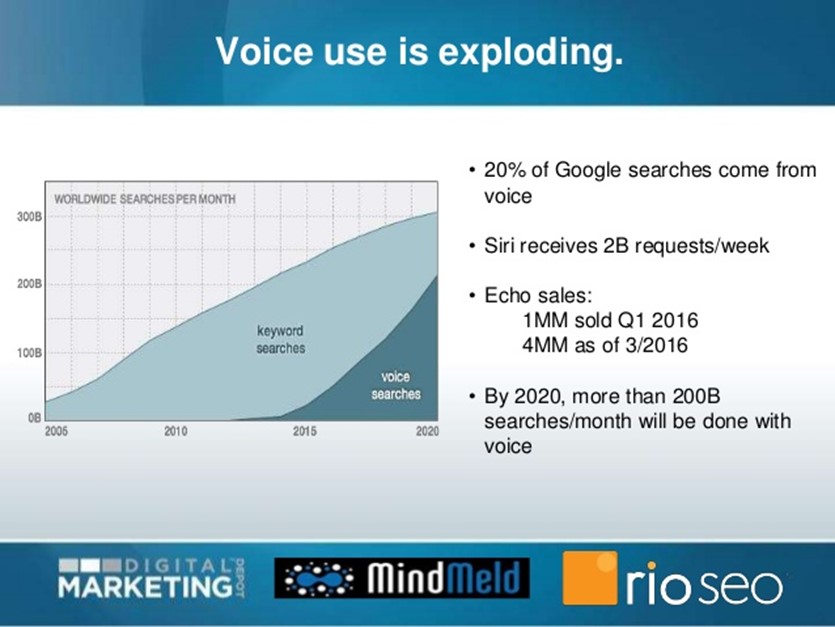
Si vous êtes encore sceptiques, sachez que 25% des 16-24ans utilisent la recherche vocale sur mobile, et connaissant la pénétration du mobile vous pouvez estimer que cela devrait devenir la norme du moins pour les jeunes.
Maintenant fait intéressant est que ces résultats vocaux proviennent presque tous de la position #0 dont nous avions parlé dans le billet « tendances SEO 2017 » selon @dannysullivan
Google Home will use Featured Snippets for answers. Source credited but not like getting a click #MadeByGoogle https://t.co/ZLMqVwHpvc pic.twitter.com/GkE7n3kovb
— Danny Sullivan (@dannysullivan) 4 octobre 2016
Alors intéressons-nous à ces fameux featured snippets et voyons voir comment obtenir ce résultat tant convoité qu’est la position Zéro.
Comment dénicher les opportunités en Featured sbippets
Pour commencer il faut espionner les concurrents. Pour cela une pléthore d’outils existent. Moi personnellement je préfère Semrush qui a un rapport pour chaque site :

On voit clairement que les mots clés « référencement de site web » et « référencement de site » sont à l’origine des featured snippets dans les SERPs :
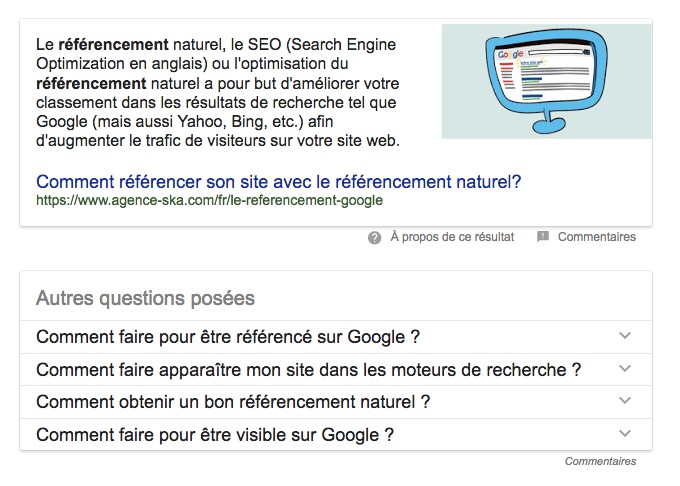
Une fois que vous en avez un qui est pertinent pour vous, vous avez presque une infinité de possibilités avec les PAAs (Autres Questions Posées). Il suffit de développer une question et Google va charger les autres questions relatives jusqu’à ce que vous dormiez 😉
Ensuite, si vous avez un domaine d’autorité suffisante pour produire des features snippets il est fort probable que vous en ayez sans vous en rendre compte. Pour cela je vous invite à consulter votre Google Search Console, de filtrer sur la position 1-2 et un CTR > 20% (éventuellement inclure les questions genre Comment, Où, Qui …etc.), de récupérer ces requêtes et de les faire rouler dans votre outil de tracking préféré (dans mon cas Semrush et Moz) pour voir celles qui génèrent une position zéro.
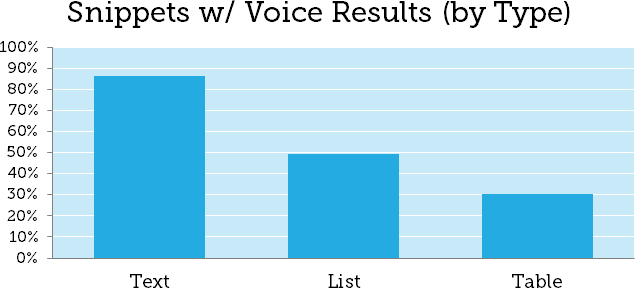
Maintenant si tout ça ne marche pas essayez donc manuellement sur Google en incorporant les questions dans votre requête sachant que le pourcentage d’affichage est comme suit :

Pour ma part j’ai réussi avec un ajustement de contenu de transformer une page normale qui apparaissait dans les résultats de recherche sous format classique en format riche comme suit :

Comment obtenir ces fameux Featured Snippets ou position zéro
Franchement il n’y a pas de secret de polichinelle quand il s’agit de revoir ou produire du nouveau contenu en optimisant pour la recherche vocale.
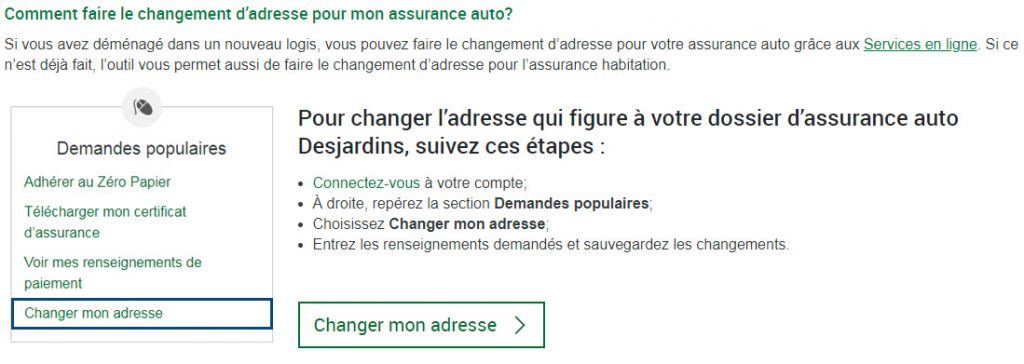
Essentiellement vous aurez besoin de bien connaître les intentions de recherche (mots clés pertinents), de structurer votre contenu de telle manière que la page affiche un ton conversationnel et de produire des résumés condensés juste après la question ensuite de développer le détail sous forme de liste, table ou paragraphe selon le cas.
Et voici la partie de la page structurée pour les questions de mon essai, avec une image de haute qualité pour illustration (très important sinon Google va piger ailleurs).
Comment optimiser vos contenus pour la recherche vocale avec Schema
Bien que Google dit ne pas vouloir dépendre des webmasters pour rendre ses résultats vocaux notamment grâce à un marquage sémantique il vient de publier au mois de Novembre 2018 un nouveau format de taggage pour la recherche vocale : Speakable Tags. Mais attention il faut que votre site soit un news website valide et seulement possible en anglais pour le moment aux US.
Notre ami @barryShwartz qui a un site de news seroundtable.com a publié une vidéo où l’on voit concrètement ce tag à l’œuvre :
Maintenant si vous développez une application Google Home ou Echo, sachez que tous les assistants ne sont pas égaux et que sans surprise Google surclasse ses concurrents en matière de performance tant à l’écoute de la question que pour les réponses fournies :

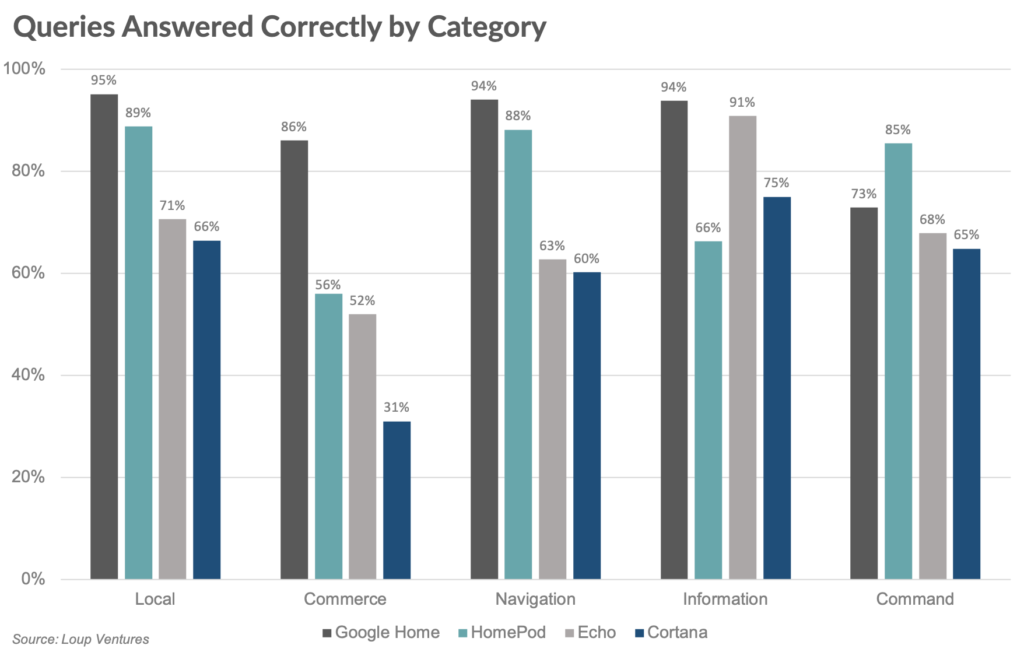
Quant à la distribution des résultats par catégorie de recherche, encore une fois sans surprise, Google est ultra performant en local, navigation et information tandis que Siri lui ravit le podium quand il s’agit de commandes comme jouer de la musique, envoyer un message ou email…etc.
Conclusion
Quel que soit votre champ d’activité en SEO, vous allez être confrontés à relever l’un de ces défis : EAT, JavaScript, Schema et Recherche Vocale. Le plus tôt vous êtes préparés le mieux c’est. Pour ma part j’avoue que j’ai des problèmes encore avec les fluctuations d’Algorithme Google (mais qui ne l’est pas étant donné qu’aucun guide n’est fourni ?)
Continuons à partager l’information c’est le meilleur rempart contre les surprises de notre ami GG et comme d’habitude je vous demanderai de rester discret et de ne partager ce billet que sur vos médias sociaux afin que mon travail soit rétribué dans une moindre mesure 😉